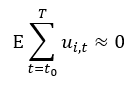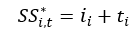Kaggle
maintains a dataset documenting over 225,000 incidents involving gun crime from
January 2014 through December 2017 across the United States. This dataset includes
the number of people injured and killed as well as the date and location of
each incident. I combined this dataset with a dataset
I already had on hand, the NICS data maintained
by the FBI on the number of background checks submitted by firearms vendors,
which I have worked with previously.
My friend from grad school, Grace Allen, also helped me locate and analyze data on the number of gun laws as well as the number of outstanding
residential firearms licenses in each state. Our goal was to determine whether any of these factors could be shown empirically to drive casualties related to gun violence.
Statewide gun laws reveal how legislation directly
affects gun violence across states. The number of outstanding firearms licenses may
serve as a proxy revealing attitudes toward guns—the more licenses outstanding
(per resident in the state), the more positive the citizenry feels about guns
generally. If these data can successfully be used to model and predict gun
violence, a level of nuance is added to some of the analyses I've performed previously with the result of deriving more interesting conclusions.
When it came down to running some statistical models, it was difficult to
draw statistically significant relationships. We tried slicing the data many
ways—modeling across states per month, across months per state, etc. But
ultimately, we think the problem is a lack in the quantity of data to make
strong conclusions. Four years of data can’t be expected to reveal long-term
trends in most cases.
In addition to the non-statistically significant results, there
were some more decisive findings, but the conclusions we could draw from them weren’t that interesting. For instance, we were able to conclude with a strong
degree of confidence that gun violence is influenced in a positive direction by
the unemployment rate in a state at any given time. But the relationship is small and most people probably could have guessed that some kind of such correlation
existed. What we really wanted were answers to bigger questions: how do
gun sales affect gun violence? Are laws effective in reducing gun violence? Does
the general statewide attitude toward firearms make a difference?
It could be that strong relationships just don’t exist in
this space. There may just be no causal link to find. But, we are open to all
ideas and will try anything that’s worth exploring. If you are interested in
seeing some of the results of the models we ran, want to suggest other ways to
use the data, or have ideas about different data sources that can be used,
please let us know by leaving comments.
Note: We don't believe the data we have on gun-related casualties is representative of every incident over the time span. For instance, there is no inclusion of accidental or self-inflicted gun violence. However, where data is missing, we assume it is randomly dispersed across all states in any given time period. This means a valid, statewide analysis can be performed.
Correlations
There were some relationships relationships that could be explored as well as some correlations anyone would be interested in seeing. We
feel it’s necessary to state that the following results are not indicative of any kind of causation. We simply go through a series of questions
and attempt to answer them with the best guesses the data can provide. For a
complete look at the dataset we used to compile these graphics, see here.
How do gun laws
affect gun violence? To answer this question, we used data maintained by
the Rand Corporation
to track how many restrictive (or non-permissive) gun laws existed in each
state in the time span we had available to us. As one might guess, there was
not a lot of variation from the first date to the last across states—states don’t
pass new restrictive laws very often. But, taking the average gun laws per
state over the 4 years as well as the average gun-violence rate (defined as
the number of casualties afflicted by gun-crime related incidents per 10,000
citizens) in each state, we constructed the following plot:

We do see a slight negative correlation—states with
more restrictive gun laws see less gun violence generally. But again, there
is a lot of variance in this relationship and the effect is small. The relationship
we do see can possibly be explained by other factors.
How do residential
licenses affect gun violence? Residential licenses outstanding per
citizen in the state can be looked at as a proxy for attitudes toward
guns—under this theory, the more licenses outstanding, the more positive that state feels
about guns. Do states which think more positively about guns see fewer
casualties? The answer is a strong “we don’t know.” There may be a slightly
negative correlation, but this was one of the least interesting relationships
we explored because the data seemed so randomly dispersed.

So, there it is. Make of it what you will.
How do the number of
background checks submitted to the FBI affect gun violence? The number of
background checks submitted for long gun and handgun purchases per 10,000
citizens was plotted against the gun-violence rate and a positive relationship
was extracted. Out of all the relationships we explored, by simply eyeballing
the data, this seemed to be the strongest:

This data can be used as a proxy for gun sales—previous
research suggests that the number of background checks submitted to
the FBI are highly correlated with the number of gun sales. But again, we can’t
make any strong conclusions about causal relationships based on the plot drawn above.
How does Washington
DC factor into all this? Washington DC appears to be an outlier in every
way. Its gun-violence rate is extremely high when compared to the states, but
there are not a lot of background checks being submitted to the FBI from there.
When it is added to the last graph displayed above, it looks like this:

By itself, it completely reverses the sign of what appeared
previously to be a somewhat strong relationship.
It’s likely that a large part of this result has to do with
the way the data is sorted. Washington DC has many qualities that are more
characteristic of a large city than a state. To start, a huge share of people
who work in DC are actually residents of surrounding states such as Maryland
and Virginia. So, any licenses or firearms registered to these commuters would
be counted under their home state, while any crimes they commit in the city
would be counted under Washington DC. Also, because the population of DC has
been reported to increase by as much as 72% during the daytime, the typical
method used to calculate per capita statistics may not fit here. For example,
if there are one million people in the city during the day, and 10 crimes
occur, then there was 1 crime for every 100,000 people present. But if the
number of crimes per capita is calculated using the number of residents (about
600,000), then this statistic could be reported at 1.6 crimes for every 100,000
people, nearly double. This effect could also be present in other large, commuter
cities like New York or Atlanta, but in those cases, the commuters are likely
commuting within their home state. Because DC does not belong to a state, it
may be forced to claim casualties that are actually more directly related to
the regulations and culture of the surrounding states than its own. It’s
important to remember that these are only hypotheses, not conclusions, and
further research would be needed to test these ideas.
Aside from data collection quirks, there are other
attributes of DC that could make it very interesting to study in terms of this
issue. Some possible reasons for the strange results may be due to DC’s status
as our nation’s capital. Washington DC is home to many prominent political
figures and government agencies, which requires that the district provide a
greater level of security than the average city. Residents of the District of
Columbia must be licensed and wait 10 days after purchasing a firearm to take
possession of it, and every firearm owned by a resident must be individually
registered with Metro PD. While the actual laws regarding the possession of
firearms in DC are on par with many other states, some of them are much more
relevant there than in other places. For example, it is illegal in all states
to carry a firearm on federal property. In most cities, this would mainly apply
to the post office and the court house, but in DC this applies to a much larger
share of the city’s buildings and land area. So, in practice, DC could be said
to have greater restrictions than most US states. DC also imposes a 10-round
limit on magazine capacity and a ban on assault rifles. The fact that DC
enforces many hotly debated gun control laws, and produced such strong and
unexpected results, suggests that it may be worth it to investigate ways to
more accurately measure the effects of gun legislation in this area.
Conclusion
As far as we are aware, no study proving a causal link
between any of the variables we explored has been accomplished. At best, there have been hypotheses made using good arguments and sound methods, but nothing that is ultimately conclusive. Therefore,
there is still an open debate about the exact nature of the relationship
between all these factors. Although we can view certain correlations, more
information, more data, or better ways of modeling the data is needed before
strong conclusions can be drawn.
We also discussed Washington DC and why it may be a case worthy of consideration by itself. It certainly appeared to be an outlier in these categories by a pure numbers’ standpoint. And we think it’s important to keep that in mind. A lot of people use Washington DC as an example of why there definitely is no relationship between gun sales, gun laws, and gun violence, or that the relationship we think exists really doesn’t, but that’s like using an exception to prove the rule. Better ways of thinking about DC is needed before it is used as an example in this domain.
In summary, we can make good guesses and create informed
hypotheses about how the relationships explored should look, but the right data
to know for sure one way or another is just not available. If you disagree or have
any other comments, feel free to let us know.
DC - Citations
If you want to research more about Washington DC, here are
the resources we used:
- General DC gun laws - https://www.pewpewtactical.com/gun-laws-state/washington-dc-gun-laws/
- Where you cannot carry in DC - https://www.pewpewtactical.com/concealed-carry-laws/washington-dc-concealed-carry-laws/
- DC daytime population - https://ggwash.org/view/34772/dcs-daytime-population-is-over-a-million
- DC daytime population - https://www.thoughtco.com/cities-see-huge-daily-population-swings-3320981
- Federal land - https://www.washingtonpost.com/graphics/local/dc-marijuana-map/